【翻译】SQL Server优化-索引
数据如何存储在SQL数据库中
数据如何物理存储在 SQL Server 中
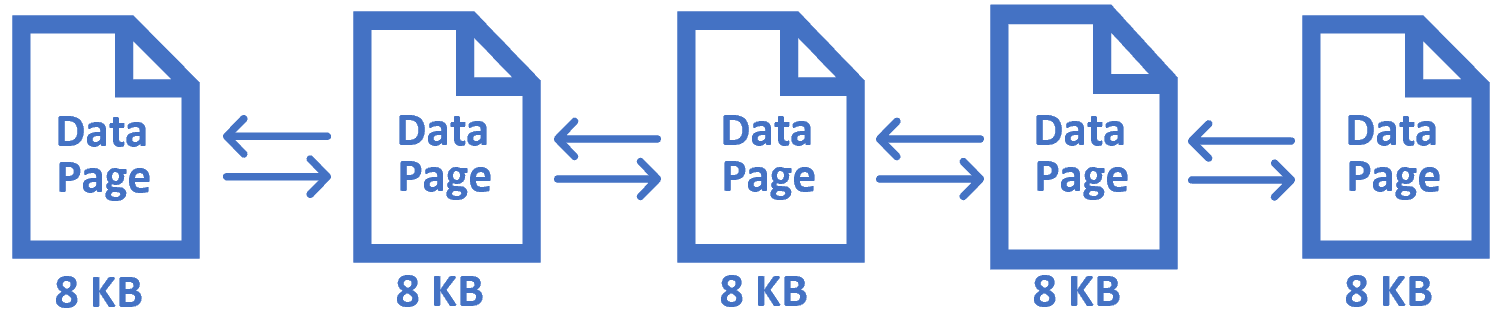
你有没有想过SQL Server 如何在内部物理存储表数据?表中的数据在逻辑上以行和列格式存储,但在物理上它将数据存储在称为数据页的东西中,数据页是 SQL Server 中数据存储的基本单位,大小为 8KB。当我们将任何数据插入到 SQL Server 数据库表中时,它会将这些数据保存到一系列 8 KB 数据页中。
SQL Server 中的数据存储在树状结构中
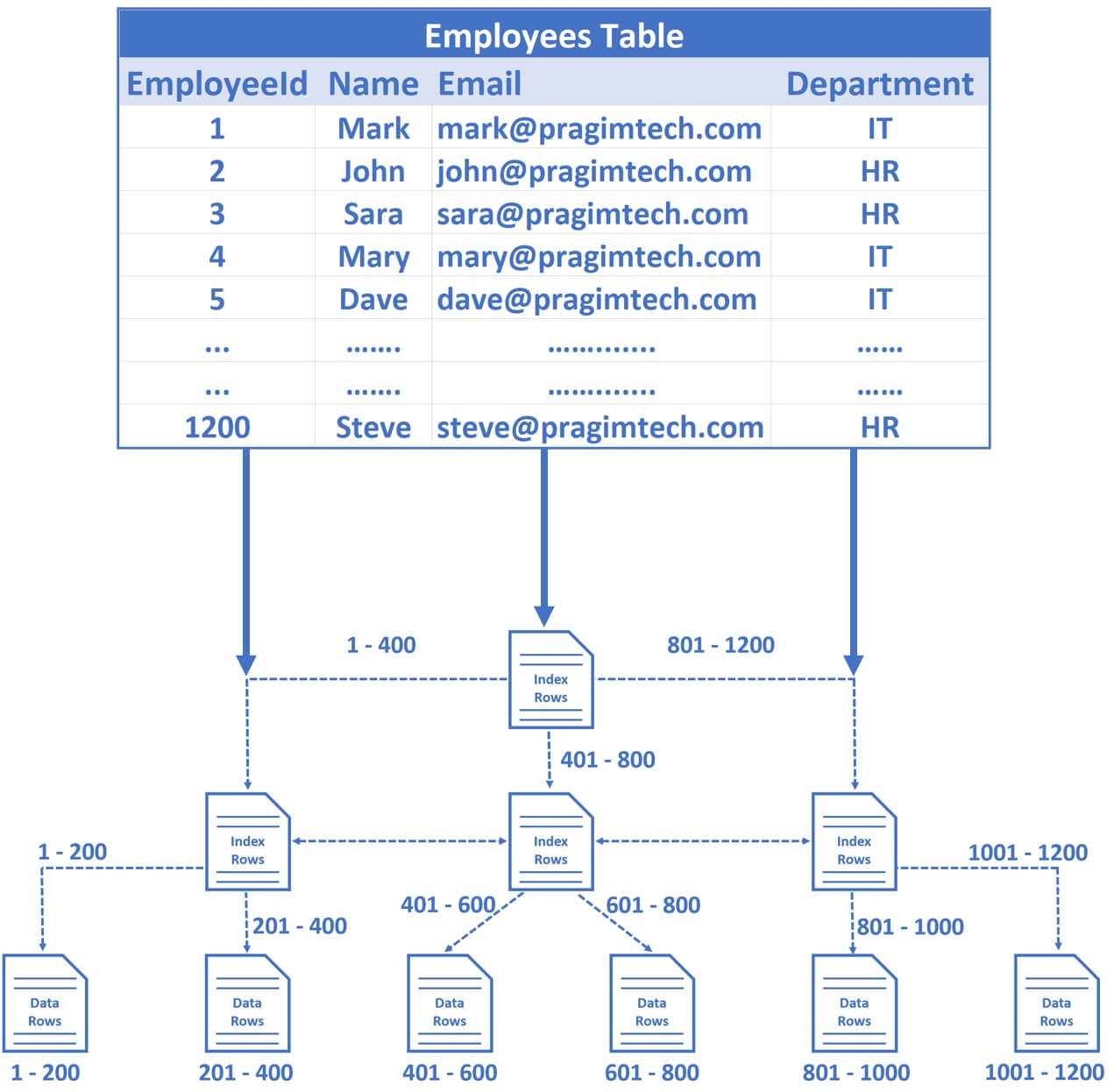
SQL Server 中的表数据实际上存储在树状结构中。我们通过一个简单的例子来理解这一点。
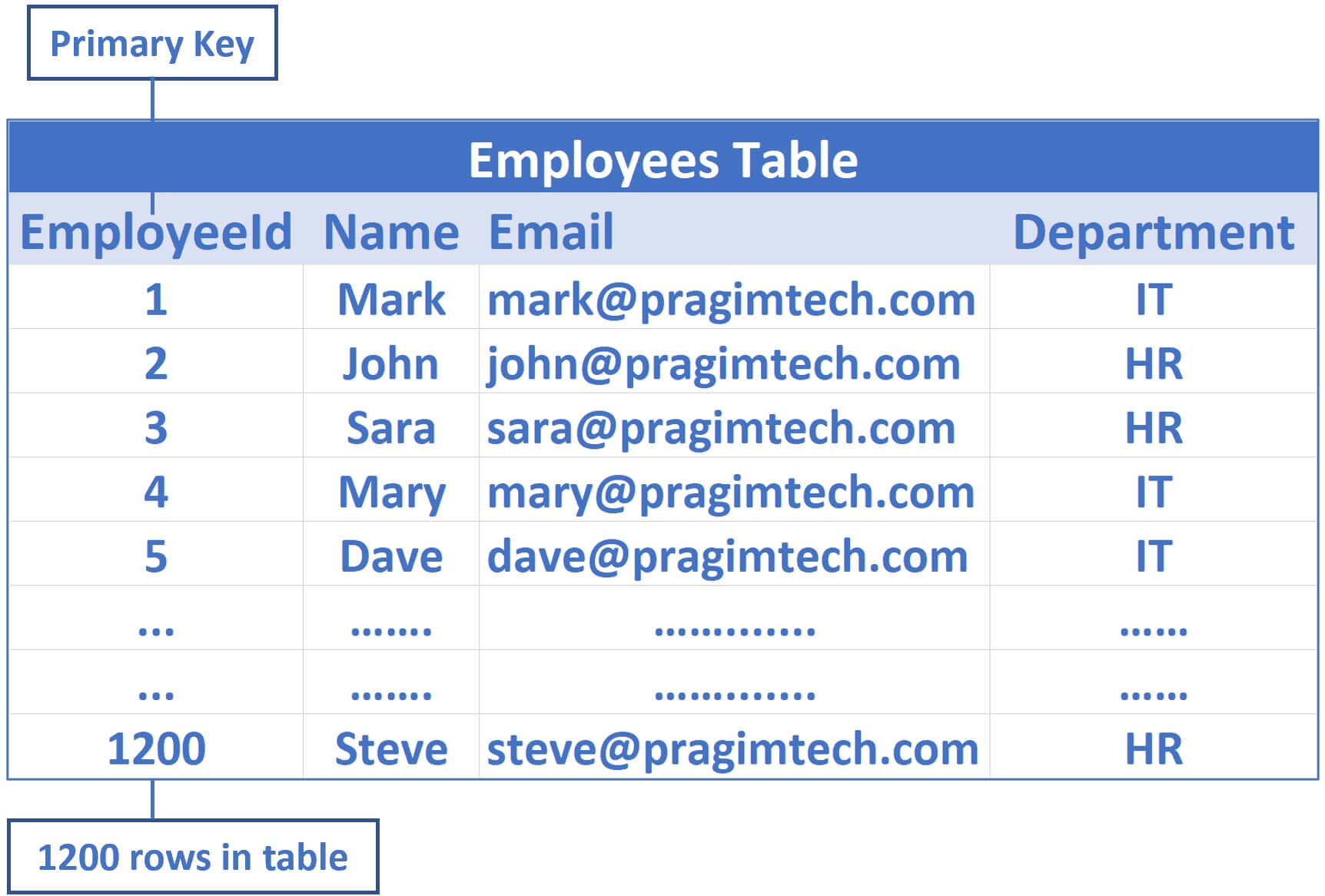
EmployeeId是主键列,所以默认情况下,会在这个EmployeeId列上创建一个聚集索引- 物理存储在数据库中的数据按
EmployeeId列排序
数据实际存储在哪里
它存储在树状结构中的一系列数据页中。如下所示。
这种树状结构称为 B-Tree、索引 B-Tree 或聚集索引结构(含义相同)。
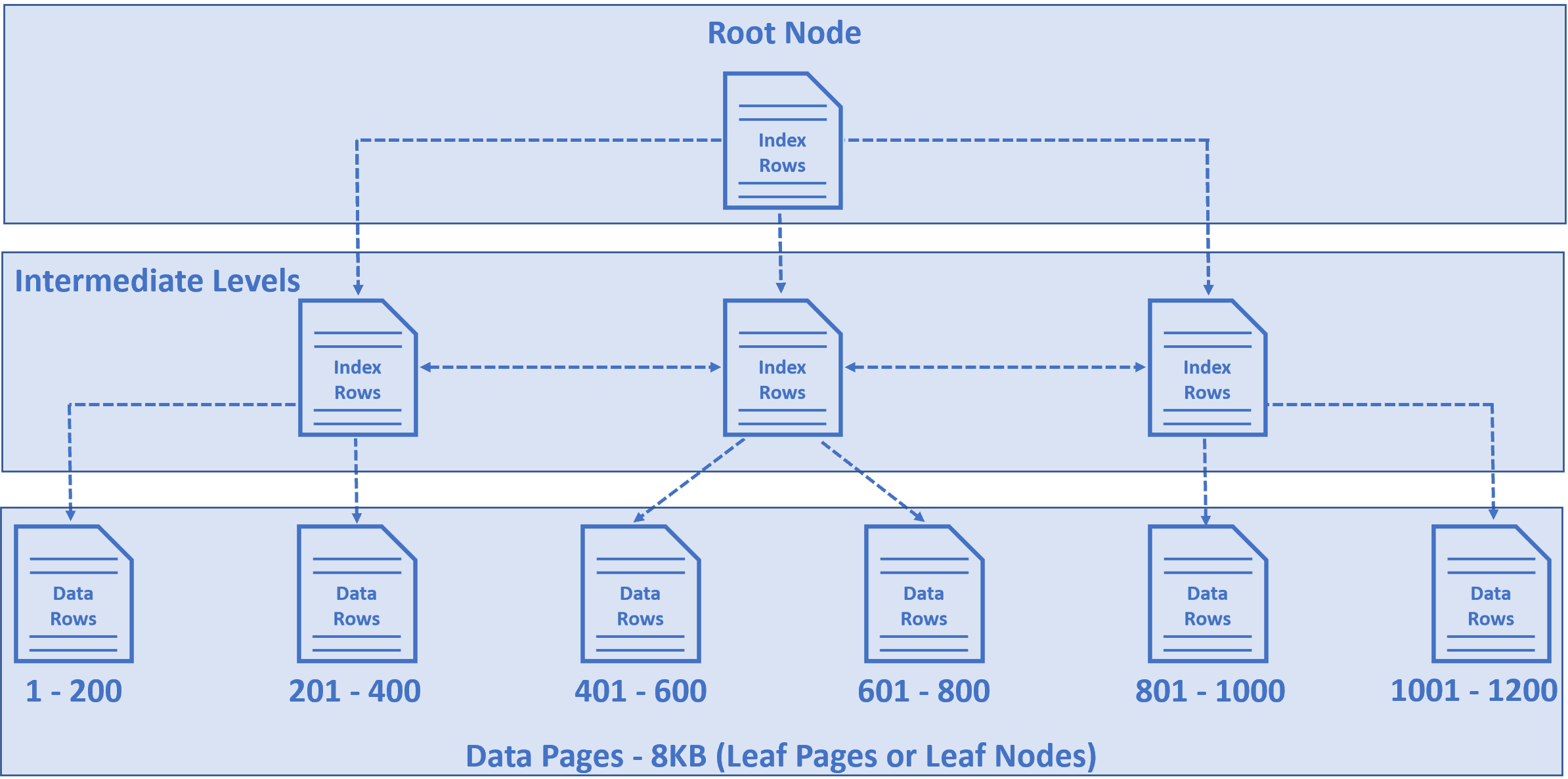
在树底部看到的节点称为数据页或树的叶节点,这些叶节点包含我们的表数据。
每个数据页的大小为 8 KB,每个数据页中存储的行数实际上取决于每行的大小。
对于上述示例,假设在 Employees 表中有 1200 行数据,在每个数据页中有 200 行数据,但实际上根据行数据的大小,数量可能会有上下浮动。我们假设每个数据页有 200 行。这些数据页中的行按 EmployeeId 列排序,因为EmployeeId是表的主键(聚集索引)。
在第一个数据页中有 1 到 200 行,在第二个数据页中有 201 到 400 行,在第三个 401 到 600 行,依此类推…
树顶部的节点称为根节点。根节点和叶节点之间的节点称为中间层,可以有多个中间层,中间层的数量取决于基础数据库表中的行数。
根节点和中间层节点包含索引行,叶节点(即树底部的节点)包含实际数据行。每个索引行包含一个键值(在我们的例子中是员工 ID)和一个指向 B Tree中的中间层或叶节点中的数据行的指针。 这种树状结构有一系列指针,可以帮助数据库引擎快速找到数据。
SQL Server 如何通过 ID 查找行
假设我们要查找 EmployeeId = 1120 的数据
1 | Select * from Employees where EmployeeId = 1120; |
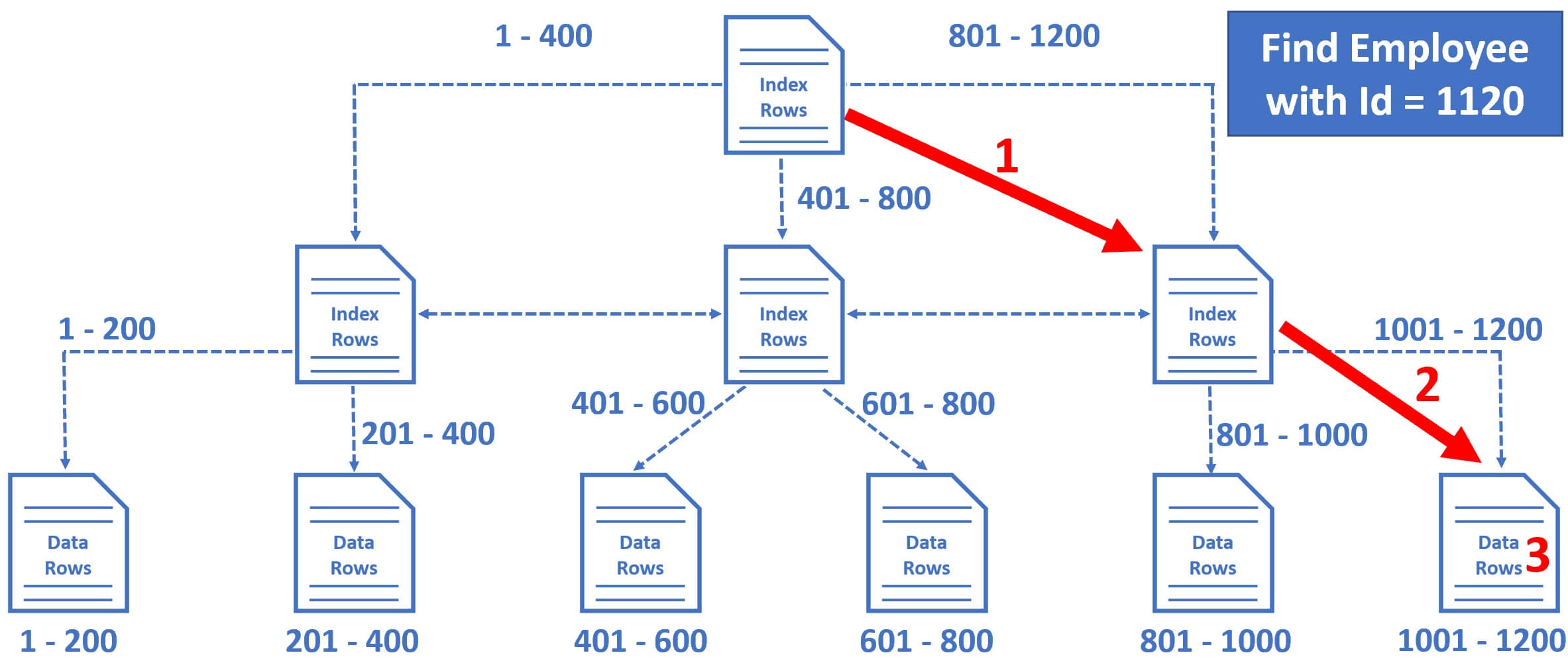
第一步:数据库引擎从根节点开始,它选择右边的索引节点,因为数据库引擎知道这个节点包含从 801 到 1200 的员工 ID。
第二步:选择最右边的叶节点,因为从 1001 到 1200 的员工数据行存在于该叶节点中。
第三步:叶节点中的数据行按员工 ID 排序,因此数据库引擎很容易找到 ID = 1120 的数据行。
只需 3 次操作,SQL Server 就能找到我们要查找的数据。如果有上百甚至上千万条记录,SQL Server 也可以方便快捷地找到我们要查找的数据,前提是有一个索引可以帮助查询查找数据。
索引是如何工作的
创建员工表
1 | Create Table Employees |
聚集索引搜索
在 SSMS 中单击Include Actual Execution Plan图标,然后执行以下查询:
1 | Select * from Employees where Id = 932000; |
实际执行计划如下:
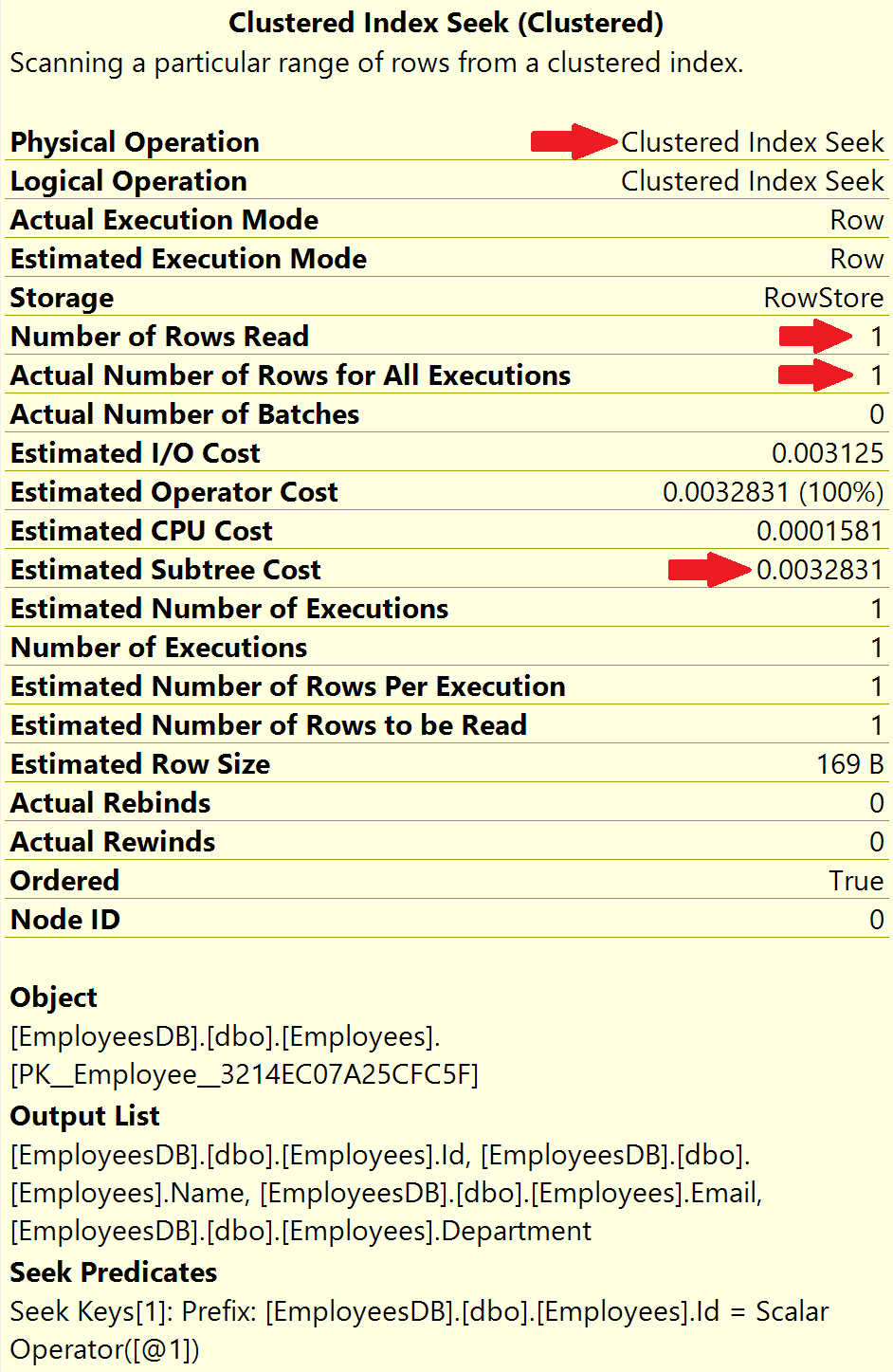
这里操作是 Clustered Index Seek,数据库引擎使用员工 Id 列上的聚集索引来查找 Id = 932000 的员工行
- Number of Rows Read (读取的行数) = 1
- Actual Number of Rows for All Executions (所有执行的实际行数 )= 1
读取的行数,是指SQL 服务器为产生查询结果而必须读取的行数。
在我们的例子中,员工 ID 是唯一的,结果集为 1 行,这由所有执行的实际行数表示。
在索引的帮助下,SQL Server 能够直接读取我们需要的 1 个特定员工行。所以,读取的行数和所有执行的实际行数都是 1。
如果有上百甚至上千万条记录,SQL Server 都可以方便快捷地找到我们要查找的数据,前提是有一个索引可以帮助查询数据。
聚集索引扫描
在这个例子中,EmployeeId 列上有一个聚集索引,当我们通过员工 id 搜索时,SQL Server 可以快速地找到我们要查找的数据。
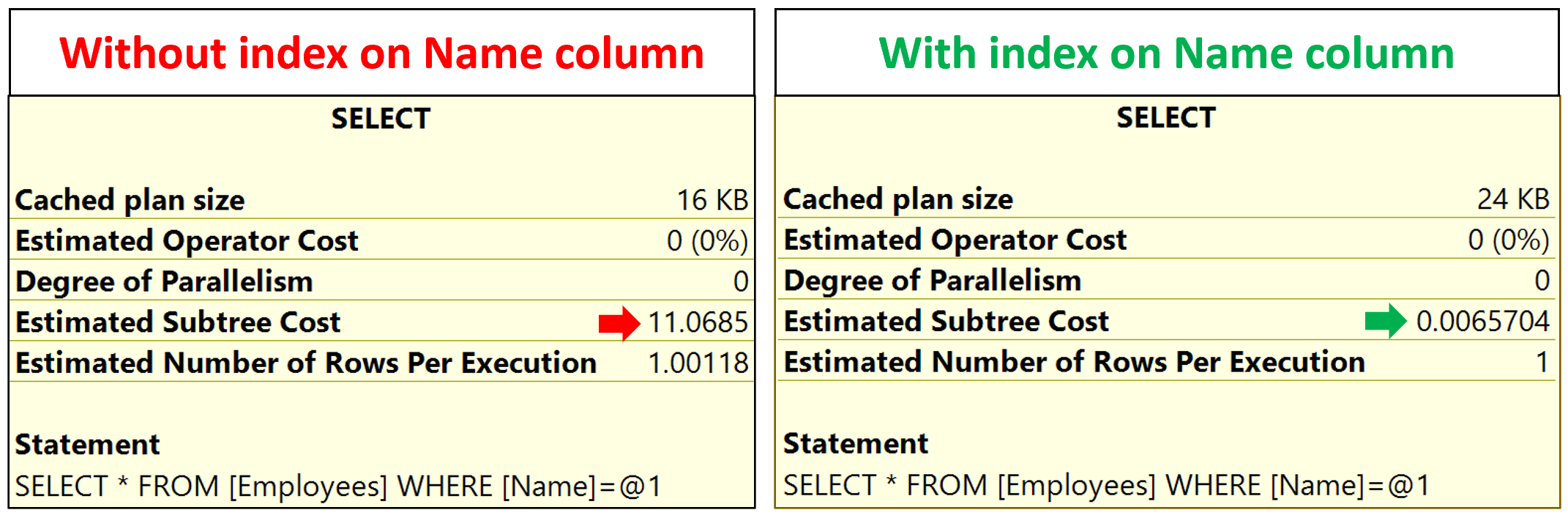
那如果我们按员工姓名搜索怎么办?Name 列上没有创建索引,因此 SQL Server 没有简单的方法找到我们要查找的数据,必须读取表中的每条记录,从性能的角度来看,效率是非常低的。
Include Actual Execution Plan在打开的情况下执行以下查询:
1 | Select * from Employees Where Name = 'ABC 932000'; |
实际执行计划如下:
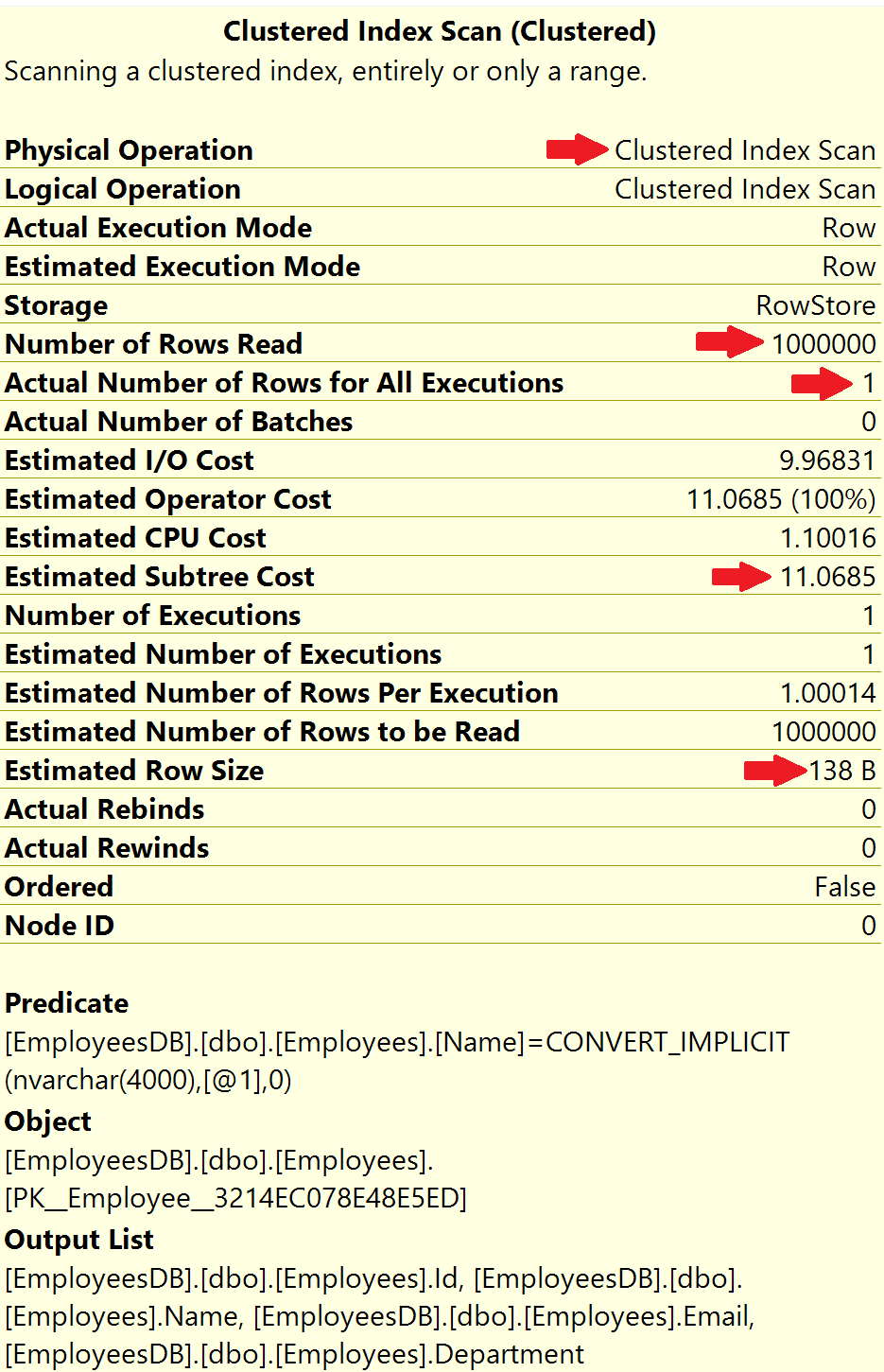
注意,这里操作的操作是Clustered Index Scan。由于没有合适的索引,数据库引擎只能读取表中的每条记录。
- Number of Rows Read (读取的行数) = 1000000
- Actual Number of Rows for All Executions (所有执行的实际行数 )= 1
我们需要的结果只有1行,只有一名员工的姓名 = ‘ABC 932000’。而要查询这一条数据,SQL Server 必须从表中读取所有的数据行。
这被称为索引扫描,索引扫描对性能有影响。
SQL Server 中的非聚集索引
在Name字段上创建非聚集索引:
1 | CREATE NONCLUSTERED INDEX IX_Employees_Name |
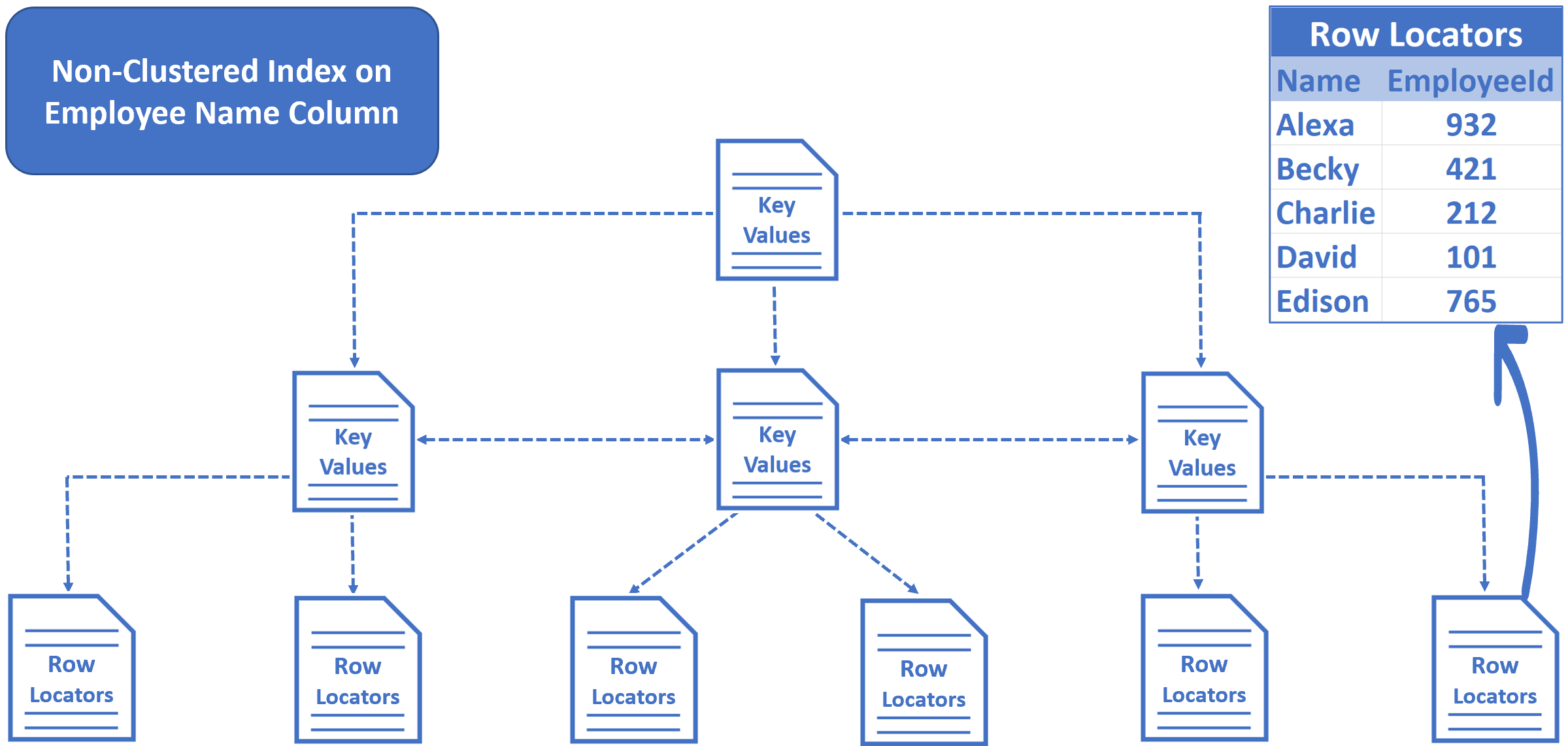
在非集群索引中,我们没有表的数据。我们有键值和行定位器。我们在 Name 列上创建了一个非聚集索引,键值(在本例中为 Employee Name)按字母顺序排序和存储。树底部的行定位器包含员工姓名和行主键,也就是Employee Id。
打开包括实际执行计划执行以下查询:
1 | Select * from Employees Where Name = 'ABC 932000'; |
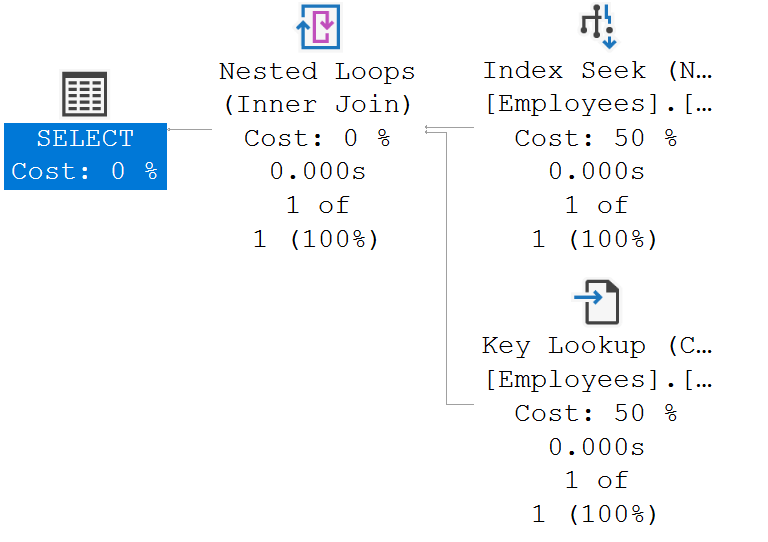
非聚集索引的运行情况
当我们执行查询:
1 | Select * from Employees where Name='David' |
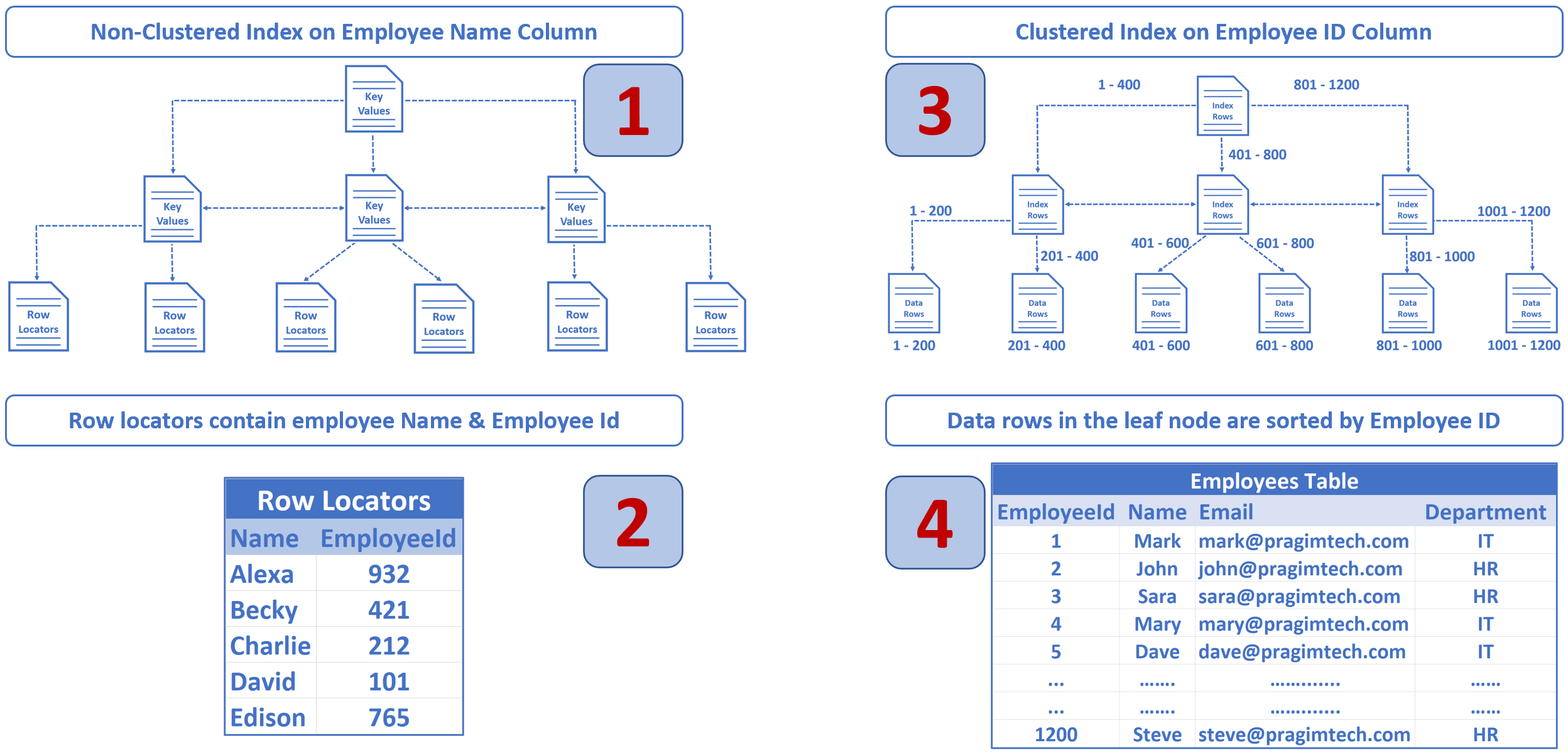
- SQL Server 使用
Name列上的非聚集索引在索引中快速找到该员工条目。 - 在非聚集索引以及员工姓名中,我们还有集群键(在我们的例子中是
Employee Id)。 - 数据库引擎知道
Employee Id上有聚集索引,使用Employee Id查找相应的员工记录。
注意:在名称列上有和没有非聚集索引的估计查询成本。